

In our first instalment, we journeyed through the evolution of data storage from traditional Data Warehouse to data lakes, leading to the emergence of the Lakehouse architecture. In the 2nd instalment, we unpacked the inner workings of the Data Lakehouse architecture, exploring the architecture principles, data ingestion, and data storage components of a modern Lakehouse. In this 3rd instalment, we will learn about generating insights from a Lakehouse.
Data Insights from a Lakehouse
Data Analytics reminds us of a treasure hunt. It’s about traversing through a forest of data to uncover valuable insights, with the river (read: domain) helping us make sense of them. This journey is especially interesting in a Lakehouse solution, which caters to two main groups:
- Technical Folks: Tech wizards who love diving deep with on-demand queries, exploring data, and writing complex machine learning algorithms.
- Functional Team Members: The guides of the treasure hunt who rely on standard reports and self-service BI tools to interpret what the forest is whispering.
Now, let’s explore the two primary flavors of analytics in a Lakehouse setup:
1. Descriptive Analytics
This type of analytics examines historical data by providing multiple perspectives. These views are created by aggregating and filtering measures and slicing data across functional dimensions such as profit centers, legal entities, customers, vendors, and products. These insights are typically delivered through Excel or visualization tools.
Examples:
- At quarter end, the finance team reconciles accounts and generates financial statements. A technical analyst runs an ad-hoc SQL query to provide a clear picture of open transactions, helping close books faster.
- Routine reporting for regulatory authorities and internal teams, often with fixed and recurring formats.
2. Advanced Analytics
Advanced analytics is futuristic. It leverages machine learning to predict outcomes and uncover complex relationships in data. It uses historical patterns to forecast trends or extract mathematical relationships for actionable insights.
The process includes:
- Exploratory Data Analysis: Mapping the terrain before the journey begins.
- Data Preparation: Crafting the right features and inputs.
- Model Development: Testing multiple algorithms to find the best-fit model.
- Model Evaluation: Validating the model using unseen data.
- Model Deployment: Putting the model in users’ hands.
Examples:
- Predicting cash flow trends or detecting unusual expense patterns.
- Identifying next best actions for collections and vendor payments.
Enabling Analytics Capabilities in a Data Lakehouse
Supporting analytics use cases within the Publish Layer requires two primary components:
- Analytical Sandbox: A virtual playground for data scientists and analysts. It runs on on-demand clusters like Apache Spark or SQL clusters. Users can query billions of records using Jupyter notebooks or similar tools. GPU-enabled clusters can support AI/ML use cases.
Example: A Finance & Accounting team improves supplier payment timelines by combining supplier, contract, and email data to build predictive models, improving supplier satisfaction.
- Business Intelligence Layer: This is where data becomes digestible for business users. Tools like Power BI, Tableau, and Qlik convert complex datasets into dashboards for decision-making.
Example: A manufacturing company’s finance team tracks raw material costs, monitors global inventory, and forecasts future expenses to stay competitive.
The beauty of the Lakehouse lies in its ability to combine heavy data processing with flexible analytics and reporting. It enables reconciliation, discrepancy detection, supply chain forecasting, and real-time operational insights.
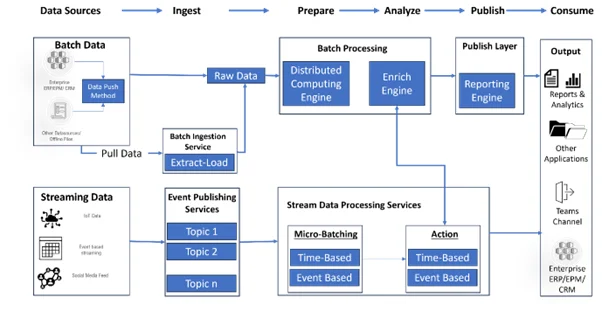
Conclusion: The Technical Symphony of Lakehouses
Lakehouse architecture is a symphony of technical components working together to manage and process data effectively. Understanding these components enables organizations to harness the full power of their data.
Midoffice Data stands at the forefront of this evolution, simplifying Lakehouse complexity for enterprises seeking agility, efficiency, and data-driven decision-making. We provide end-to-end capabilities from ingestion to storage and serving layers tailored for enterprise data ecosystems.
Stay tuned for the final part of this series on Data Security and Governance in Lakehouse architecture. Meanwhile, if you would like to explore how astRai can strengthen your data strategy, reach out to us.
References:
What is a Data Lakehouse? – Databricks
- Data Lakehouse in Action by Pradeep Menon
Data Architecture: Complex vs Complicated